Пример из области медицины
В завершении приводится классификационная таблица с указанием достигнутой точности прогнозирования. Значение этой точности равно 68.7%, что является неудовлетворительным:
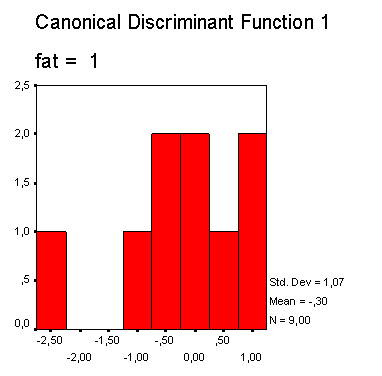
Рис. 18.2: Распределение значений дискриминантной функции для группы "скончался"
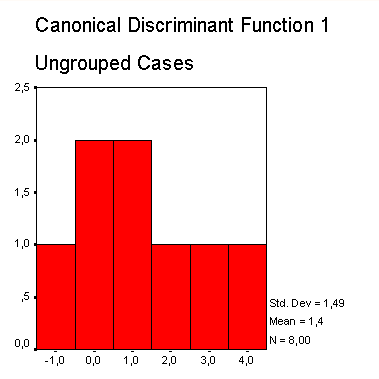
Рис. 18.3: Распределение значений дискриминантной функции для группы "выжил"
Classification Results 3 (Классификационные результаты)
| Outcome (Исход) | Predicted Group Membership (Предсказанная принадлежность к одной из групп) | Total (Сумма) | |||
| gestorben (Скончался) | ueberlebt (Выжил) | ||||
| Original Перво-начально) | Count (Количество) | gestorben (скончался | 38 | 25 | 63 |
| ueberlebt (Выжил) | 16 | 52 | 68 | ||
| % | gestorben (скончался | 60.3 | 39.7 | 100.0 | |
| ueberlebt (Выжил) | 23.5 | 76.5 | 100.0 | ||
- а. 68.7% of original grouped cases correctly classified (68.7% первоначально сгруппированных наблюдений были классифицированы корректно).
При применении метода логарифмической регрессии (см. гл. 16.4) результат получился немного лучше (доля корректного прогноза 70.99%).
Для случая, когда пациенту мужского пола, 25 лет, ростом 184 см искусственное дыхание делали на протяжении 5 часов, при концентрации кислорода равной 0.7 и интенсивности соответствующей значению 10, получается следующее значение дискриминантной функции:
d = 2.121 + 0.033 * 10 + 0.04 * 25 + 0.06 * 5 + 0.133 * 1 - 0.041 * 184 + 2.539 * 0.7 = -1.883Опираясь на распределение значений дискриминантной функции, этого пациента можно отнести к группе выживших.
При выполнении дискриминантного анализа, как и для других многомерных процедур, можно применять и пошаговый образ действий, который как раз и рекомендуется при наличии большого количества независимых переменных. Этот метод похож на многомерный регрессионный анализ, однако переменные при проведении дискриминантного анализа выбираются по другим критериям.
Рассчитаем еще раз наш пример, но уже с применением пошагового метода.
- В исходном диалоговом окне дискриминантного анализа активируйте опцию Use stepwse method (Использовать пошаговый метод).
- Щелкните на кнопке Method… (Метод)
Откроется диалоговое окно Discriminant Analysis: Step-wise Method (Дискриминантаый анализ: Пошаговый метод).
- Выберите метод, при помощи которого будет отобрана та переменная, которая увеличивает расстояние Махаланобиса (Mahalanobis) между двумя группами. Эта дистанционная мера базируется на евклидовых расстояниях между нормализованными значениями выборок с учетом корреляции соответствующих переменных.
- Чтобы искусственно не раздувать объем выводимых результатов, в этот раз через кнопку Classify… (Классифицировать), активируйте опцию Summary table (Сводная таблица).
В рассматриваемом случае мы отказываемся от графического представления результатов. В анализ по очереди будут включены переменные: bzeit, gr, Alyer и kob; это те же самые переменные, которые использовались при применении метода логистической регрессии. По заключительной классификационной таблице можно сделать вывод о том, что в результате отбрасывания неподходящих переменных доля попаданий слегка выросла. Значение надежности прогноза составило 70.2%.
Для проведения дискриминантного анализа Вы можете использовать и пример с двумя диагностическими тестами для обнаружения карциномы мочевого пузыря, рассмотренный в главе 16.4. Здесь можно получить более четкое разделение двух групп (здоров – болен). Точность прогнозирования здесь составляет 82.2%.