Форматирование данных
Между тем, что мы хотим сказать компьютеру ("реши мою проблему"), и тем, что нам приходится ему говорить для достижения нужного результата, всегда существует некоторый разрыв. Очевидно, что чем этот разрыв меньше, тем лучше. Хорошая нотация поможет нам сказать именно то, что мы хотели, и препятствует ошибкам. Иногда хороший способ записи освещает проблему в новом ракурсе, помогая в ее решении и подталкивая к новым открытиям.
Малые языки (little languages) – это нотации для узких областей применения. Эти языки не только предоставляют удобный интерфейс, но и помогают организовать программу, в которой они реализуются. Хорошим примером является управляющая последовательность printf:
printf("%d %6.2f %-10.10s\n", f, s);
Здесь каждый знак процента обозначает место вставки значения следующего аргумента printf; за ним следуют необязательные флаги и размеры поля и, наконец, буква, которая указывает тип параметра. Такая нотация компактна, интуитивно понятна и легка в использовании; ее реализация достаточно проста и прямолинейна. Альтернативные возможности в C++ (lost ream) и Java (java.io) выглядят гораздо менее привлекательно, поскольку они не предоставляют специальной нотации, хотя могут расшириться типами, определяемыми пользователем, и обеспечивают проверку типов.
Некоторые нестандартные реализации printf позволяют добавлять свои приведения типов к встроенным. Это удобно, когда вы работаете с другими типами данных, нуждающимися в преобразованиях при вызове. Например, компилятор может использовать знак %1_ для обозначения номера строки и имени файла; графическая система – использовать >>Р для точки, a %R – для прямоугольника. Строка шифра из букв и номеров – сведения о биржевых котировках, которая рассматривалась нами главе 4, относится к тому же типу: это компактный способ записи таких котировок.
Схожие примеры можно придумать и для С и C++. Представим себе, что нам нужно пересылать пакеты, содержащие различные комбинации типов данных, из одной системы в другую. Как мы видели в главе 8, самым чистым решением была бы передача данных в текстовом виде. Однако для стандартного сетевого протокола лучше иметь двоичный формат по причинам эффективности и размера. Как же нам написать код для обработки пакетов, чтобы он был переносим, эффективен и прост в эксплуатации?
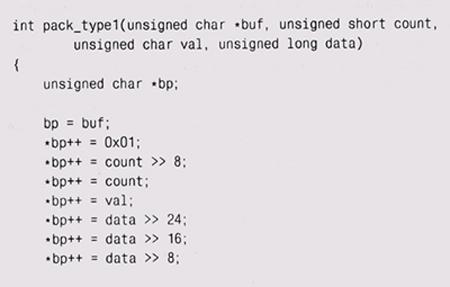
Для того чтобы дальнейшее обсуждение было конкретным, представим себе, что нам надо пересылать пакеты из 8-битовых, 16-битовых и 32-битовых элементов данных из одной системы в другую. В стандарте ANSI С оговорено, что в char может храниться как минимум 8 битов, 16 битов может храниться в short и 32 бита – в long, так что мы, не мудрствуя лукаво, будем использовать именно эти типы для представления наших данных. Типов пакетов может быть много: пакет первого типа содержит однобайтовый спецификатор типа, двухбайтовый счетчик, однобайтовое значение и четырехбайтовый элемент данных:
— Регулярная проверка качества ссылок по более чем 100 показателям и ежедневный пересчет показателей качества проекта.
— Все известные форматы ссылок: арендные ссылки, вечные ссылки, публикации (упоминания, мнения, отзывы, статьи, пресс-релизы).
— SeoHammer покажет, где рост или падение, а также запросы, на которые нужно обратить внимание.
SeoHammer еще предоставляет технологию Буст, она ускоряет продвижение в десятки раз, а первые результаты появляются уже в течение первых 7 дней. Зарегистрироваться и Начать продвижение

Пакет второго типа может состоять из одного короткого и двух длинных слов данных:

Один из способов – написать отдельные функции упаковки и распаковки для каждого типа пакета: