
Воровство в Web
В главе 1 описан предварительный сбор данных, позволяющий получить максимально полную информацию об отдельном узле или обо всей сети в целом. Воровство в Web преследует практически ту же цель. В поисках информации взломщики вручную просматривают Web-страницы, стараясь найти недостатки в коде, зацепки в комментариях и дизайне. В этом разделе приведено несколько способов такого сбора информации о Web-сервере. В число этих методов входит последовательный просмотр страниц вручную, применение сценариев автоматизации и коммерческих программ.
Последовательный просмотр страниц
Один из давно известных способов получения данных заключался в прохождении всего Web-узла вручную, просматривая в браузере исходный код каждой страницы. В документах HTML можно найти огромное количество информации, включая ценные комментарии, адресованные другим разработчикам, адреса электронной почты, номера телефонов, программы JavaScript и многое другое. Например, задав в браузере адрес какого-нибудь сервера и выбрав команду View › Page Source, можно увидеть исходный код HTML (рис. 15.1).
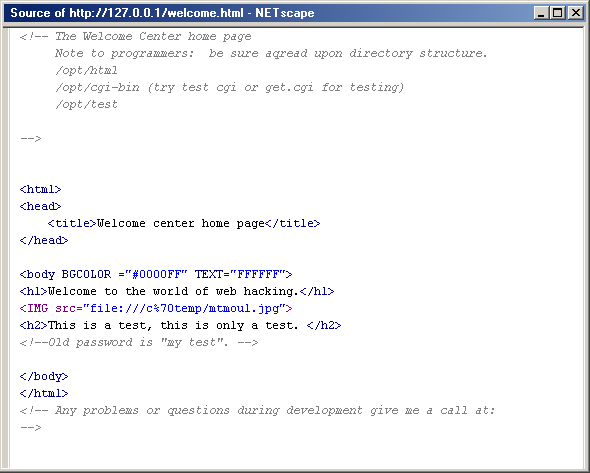
Рис. 15.1. Исходный код HTML может содержать много важной информации. Зачастую в нем содержится структура каталогов, номера телефонов, имена и адреса электронной почты разработчиков Web-страниц
Упрощай!
К крупным Web-узлам (содержащим более 30 страниц) большинство взломщиков применяют автоматизированный подход, используя специальные сценарии или утилиты. Сценарии можно писать на различных языках, однако авторы отдают предпочтение языку Perl. С помощью несложных программ на этом языке можно перемещаться по Web-серверу, осуществляя поиск определенных ключевых слов.
Для копирования данных такого типа разработано также несколько коммерческих программ как для системы UNIX, так и для NT. Наиболее популярной является утилита Teleport Pro для NT, разработанная компанией Tennyson Maxwell Information Systems (http://www.tenmax.com), диалоговое окно которой показано на рис. 15.2. Эта программа позволяет отобразить целый Web-узел на локальный компьютер для дальнейшего ознакомления.
Для более подробного анализа файлов, удовлетворяющих критерию поиска, можно загрузить их локально. Например, если нужно найти Web-страницы, которые содержат определенные ключевые слова (пусть даже в исходном коде HTML), такие как email, contact, user*, pass*, updated и так далее, то это можно осуществить с помощью утилиты Teleport Pro. При этом поиск по любому из этих слов можно вести только в файлах определенного типа, например *.htm. *.html, *.shtm, *.shtml, *.txt. '.cfm и т.д. На следующем рисунке показано, как в программе Teleport Pro задать тип файлов, в которых следует осуществлять поиск.
Рис. 15.2. Программа Tclepon для системы NT
— Регулярная проверка качества ссылок по более чем 100 показателям и ежедневный пересчет показателей качества проекта.
— Все известные форматы ссылок: арендные ссылки, вечные ссылки, публикации (упоминания, мнения, отзывы, статьи, пресс-релизы).
— SeoHammer покажет, где рост или падение, а также запросы, на которые нужно обратить внимание.
SeoHammer еще предоставляет технологию Буст, она ускоряет продвижение в десятки раз, а первые результаты появляются уже в течение первых 7 дней. Зарегистрироваться и Начать продвижение
Эта программа позволяет задавать также слова, которые необходимо найти.
Как только нужные Web-страницы будут скопированы на локальный компьютер, взломщик сможет приступить к их исследованию. При этом он будет изучать каждую страницу HTML, каждый графический файл, панель управления и встроенные сценарии, стараясь разобраться с архитектурой исследуемого Web-узла. Эти сведения впоследствии могут оказаться очень полезными.
Контрмеры против воровства в Web
- Регулярно анализируйте содержимое журналов регистрации и следите за повышением количества запросов GET, поступающих из одного и того же источника.
- Используйте сценарий garbage.cgi, выдающий нескончаемый поток случайных данных в том случае, если какая-нибудь автоматическая программа начнет исследование узла и будет запускать сценарии CGI. Конечно, с помощью утилиты Teleport Pro эту проблему можно обойти, но взломщикам по крайней мере придется хорошо потрудиться.