
Упаковка данных
Наиболее универсальны так называемые арифметические алгоритмы, которые находят и устраняют все автокорреляции, присутствующие во входных данных. Математическое обоснование и принципы работы этих алгоритмов заслуживают отдельной книги и увели бы нас далеко в сторону от темы. К сожалению, из-за больших вычислительных затрат эти алгоритмы и реализующие их программы не получают широкого распространения.
Все перечисленные алгоритмы способны только устранять автокорреляции, уже существующие во входном потоке. Понятно, что если автокорреляций не было, то упаковки не произойдет, поэтому гарантировать уровень упаковки эти алгоритмы не могут.
Для упаковки данных, полученных оцифровкой реальных сигналов, прежде всего изображений и звука, точные алгоритмы не подходят совершенно. Дело в том, что реальный сигнал всегда сопровождается тепловым, так называемым белым (равномерно содержащим все частоты) шумом. Этот шум искажает наличествующие в сигнале автокорреляции, сам же автокорреляций не имеет, поэтому обратимые алгоритмы с зашумленным сигналом справиться не могут.
Чтобы убедиться в этом, можно попробовать упаковать любым, или даже несколькими из распространенных архиваторов трек аудио-CD или цифровую фотографию впрочем, чтобы с цифровой фотографией фокус получился, необходимо, чтобы кадр был снят без обработки встроенным упаковщиком камеры.
Идея обширного семейства алгоритмов, пригодных для сжатия зашумлен-ных сигналов, была позаимствована из принципа работы цифровых фильтров-"шумодавов". Шумодав работает следующим образом: он осуществляет над сигналом преобразование Фурье и удаляет из полученного спектрального образа самые слабые частоты, которые ниже порога подавления.
Сигнал при этом, конечно, искажается, но сильнее всего при этом страдает равномерно распределенный по спектру шум, что и требуется (рис. 1.8).
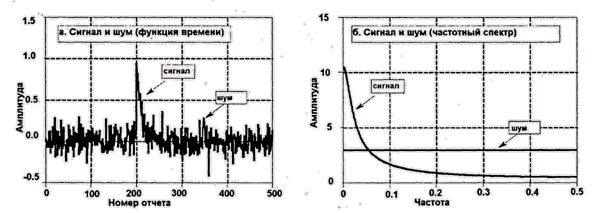
Рис. 1.8. Зашумленный сигнал и его спектральный образ (результат преобразования Фурье), цит. по [Smith 1997]
Алгоритмы JFIF (лежащий в основе распространенного формата хранения растровых изображений JPG), MPEG, MP3 [www.jpeg.org] тоже начинаются с выполнения над входным потоком преобразования Фурье. Но, в отличие от шумодава, JFIF удаляет из полученного спектра не частоты, которые ниже заданного порога, а фиксированное количество частот – конечно же, стараясь отобрать самые слабые. Количество частот, которые надо выкинуть, определяется параметром настройки упаковщика. У JFIF этот параметр так и называется – коэффициентом упаковки, у МРЗ – битрейтом.
— Регулярная проверка качества ссылок по более чем 100 показателям и ежедневный пересчет показателей качества проекта.
— Все известные форматы ссылок: арендные ссылки, вечные ссылки, публикации (упоминания, мнения, отзывы, статьи, пресс-релизы).
— SeoHammer покажет, где рост или падение, а также запросы, на которые нужно обратить внимание.
SeoHammer еще предоставляет технологию Буст, она ускоряет продвижение в десятки раз, а первые результаты появляются уже в течение первых 7 дней. Зарегистрироваться и Начать продвижение
Профильтрованный сигнал заведомо содержит автокорреляции – даже если исходный, незашумленный, сигнал их и не содержал, такая фильтрация их создаст – и потому легко поддается упаковке. Благодаря этому, все перечисленные алгоритмы обеспечивают гарантированный уровень упаковки. Они способны сжать в заданное число раз даже чистый белый шум. Понятно, что точно восстановить по подвергнутому такому преобразованию потоку исходный сигнал невозможно, но такой цели и не ставится, поэтому все перечисленные методы относятся к разряду необратимых.
При разумно выбранном уровне упаковки результат – фотореалистичное изображение или музыкальное произведение – на взгляд (или, соответственно, на слух) практически неотличим от оригинала. Различие может показать только спектральный анализ данных. Но если распаковать сжатое с потерями изображение, подвергнуть его редактированию (например, отмасштабировать или пририсовать какой-нибудь логотип), а потом упаковать снова, результат будет удручающим: редактирование привнесет в изображение новые частоты, поэтому велика опасность, что повторная упаковка даже с более низким коэффициентом сжатия откусит какие-то из "полезных" частот изображения. После нескольких таких перепаковок от изображения остается только сюжет, а от музыки – только основной ритм. Поэтому всерьез предлагается использовать приблизительные алгоритмы упаковки в качестве механизма зашиты авторских прав: в спорной ситуации только настоящий автор произведения может предъявить его исходный, неупакованный вариант.
Экспериментальные варианты приблизительных алгоритмов вместо классического разложения по взвешенной сумме синусов и косинусов используют разложение по специальным функциям, так называемым вэйвлетам (wavelet). Утверждается, что вэйвлетная фильтрация при том же уровне сжатия (понятно, что сравнивать по уровню сжатия алгоритмы, которые сжимают что угодно в заданное число раз, совершенно бессмысленно) дает меньший уровень субъективно обнаружимых искажений. Но субъективное восприятие, как известно, сильно подвержено эффекту плацебо (человек склонен видеть улучшение или вообще изменение там, где его нет, если имеет основания предполагать, что изменение должно произойти), зато вэйвлетные алгоритмы сильно уступают обычным вариациям JFIF по производительности, поэтому до сих пор они не вышли из экспериментального состояния.