
Алгоритмы динамического управления памятью
Фактически, парные метки можно рассматривать как способ реализации решения, предложенного нами как одна из идей мозгового штурма: двунаправленного списка, включающего в себя как занятые, так и свободные блоки, и отсортированного по адресу. Дополнительное преимущество приведенного алгоритма состоит в том, что мы можем отслеживать такие ошибки, как многократное освобождение одного блока, запись в память за границей блока и иногда даже обращение к уже освобожденному блоку. Действительно, мы в любой момент можем проверить всю цепочку блоков памяти и убедиться в том, что все свободные блоки стоят в списке, что в нем стоят только свободные блоки, что сами цепочка и список не испорчены и т. д.
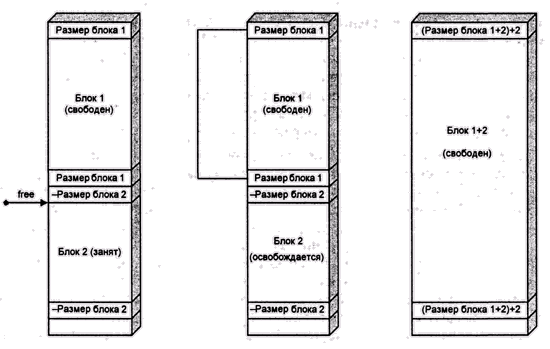
Рис. 4.8. Объединение с использованием парных меток
Примечание
Это действительно большое преимущество, так как оно значительно облегчает выявление ошибок работы с указателями, о которых в руководстве по Zortech C/C++ сказано, что "опытные программисты, услышав это слово [ ошибка работы с указателями – прим. авт.], бледнеют и прячутся под стол" ([Zortech v3.xj).
Итак, наилучшим из известных универсальных алгоритмов динамического распределения памяти является алгоритм парных меток с объединением свободных блоков в двунаправленный кольцевой список и поиском по принципу first fit. Этот алгоритм обеспечивает приемлемую производительность почти для всех стратегий распределения памяти, используемых в прикладных программах.
Алгоритм парных меток был предложен Дональдом Кнутом в начале 60-х. В третьем издании классической книги [Кнут, 2000], этот алгоритм приводится под названием "освобождения с дескрипторами границ". В современных системах используются и более сложные структуры дескрипторов, но всегда ставится задача обеспечить поиск соседей блока по адресному пространству за фиксированное время. В этом смысле, практически все современные подпрограммы динамического выделения памяти (в частности, реализации стандартной библиотеки языка С) используют аналоги алгоритма парных меток. Другие известные подходы либо просто хуже, чем этот, либо проявляют свои преимущества только в специальных случаях.
Реализация maiioc в библиотеке GNU LibC (реализация стандартной библиотеки языка С в рамках freeware проекта GNU Not Unix) (пример 4.3) использует смешанную стратегию: блоки размером более 4096 байт выделяются стратегией first fit из двусвязного кольцевого списка с использованием циклического просмотра, а освобождаются при помощи метода, который в мазанном ранее смысле похож на алгоритм парных меток. Все выделяемые образом блоки будут иметь размер, кратный 4096 байтам.
Блоки меньшего размера объединяются в очереди с размерами, пропорциональными степеням двойки, как в описанном далее алгоритме близнецов. Элементы этих очередей называются фрагментами (рис. 4.9). В отличие от алгоритма близнецов, мы не объединяем при освобождении парные фрагменты. Вместо этого, мы разбиваем 4-килобайтовый блок на фрагменты одинакового размера. Если, например, наша программа сделает запросы на 514 и 296 байт памяти, ей будут переданы фрагменты в 1024 и 512 байт соответственно. Под эти фрагменты будут выделены полные блоки в 4 килобайта, и внутри них будет выделено по одному фрагменту. При последующих запросах на фрагменты такого же размера будут использоваться свободные фрагменты этих блоков. Пока хотя бы один фрагмент блока занят, весь блок считается занятым. Когда же освобождается последний фрагмент, блок возвращается в пул.
— Регулярная проверка качества ссылок по более чем 100 показателям и ежедневный пересчет показателей качества проекта.
— Все известные форматы ссылок: арендные ссылки, вечные ссылки, публикации (упоминания, мнения, отзывы, статьи, пресс-релизы).
— SeoHammer покажет, где рост или падение, а также запросы, на которые нужно обратить внимание.
SeoHammer еще предоставляет технологию Буст, она ускоряет продвижение в десятки раз, а первые результаты появляются уже в течение первых 7 дней. Зарегистрироваться и Начать продвижение
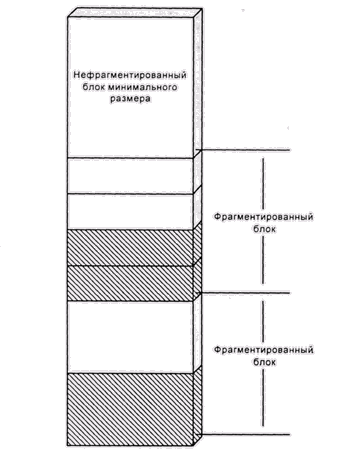
Рис. 4.9. Фрагменты в реализации malloc из GNU LibC