
Дерево
Включение узла в упорядоченное бинарное дерево
Задача включения узла в дерево уже была решена нами при построении дерева. Осталось оформить соответствующий фрагмент программы в виде отдельной процедуры addNodeTree. Чтобы не дублировать код, разработаем рекурсивный вариант процедуры включения – addNodeTree. Он хоть и не так нагляден, как нерекурсивный вариант кода в программе prg_03.asm, но выглядит достаточно профессионально.
Работу процедуры addNodeTree можно проверить с помощью программы prg02_ 13.asm.
В результате проведенных работ мы получили дублирование кода, строящего и дополняющего дерево. В принципе для строительства и включения в дерево достаточно одной процедуры addNodeTree. Но в учебных целях мы ничего изменять не будем, чтобы иметь два варианта строительства дерева – рекурсивный и не рекурсивный. При необходимости читатель сам определит, какой из вариантов более всего отвечает его задаче и в соответствии с этим доработает этот код.
Исключение узла из упорядоченного бинарного дерева
Эта процедура более сложная. Причиной тому то обстоятельство, что существует несколько вариантов расположения исключаемого узла в дереве: узел является листом, узел имеет одного потомка и узел имеет двух потомков. Самый непростой случай – последний. Процедура удаления элемента del NodeTree является рекурсивной и, более того, содержит вложенную процедуру del, которая также является рекурсивной.
Работу этой процедуры можно проверить с помощью программы prg02_13.asm.
Графически процесс исключения из дерева выглядит так, как показано на рис. 2.20. Исключаемый узел помечен стрелкой.
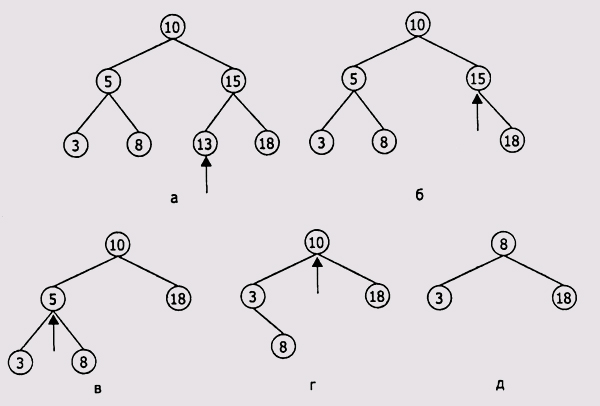
Рис. 2.20. Исключение из дерева
Для многих прикладных задач, занимающихся обработкой символьной информации, важное значение могут иметь так называемые лексикографические деревья. Для нашего изложения они важны тем, что эффективно могут быть применены при разработке трансляторов, чему мы также уделим внимание в этой книге.
Лексикографическое дерево
Деревья поиска, подобные лексикографическим, являются альтернативой методам поиска, основанным на хэшировании. Структурно лексикографическое дерево представляет собой бинарное дерево поиска. Рассмотрим задачу, которая заключается в анализе некоторого текстового файла и сборе статистики о частоте встречаемости слов в этом тексте. В качестве итога требуется вывести на экран информацию о частоте встречаемости каждого слова. В такой постановке задачи программа будет состоять из следующих частей.
- Чтение текстового файла и построение соответствующего ему лексикографического дерева. Для этого будем читать и проверять на предмет новизны каждое слово в анализируемом тексте. Если слово встретилось впервые, то необходимо сформировать и внести в дерево узел, который структурно состоит из двух полей: поля для хранения самого слова и поля для хранения частоты встречаемости этого слова в тексте.
- Для вывода на экран статистики необходимо совершить левосторонний обход дерева. Если изменить условия вывода статистики, например упорядочить слова по частоте встречаемости в тексте, то необходимо выполнить перестроение дерева и его последующий правосторонний обход.
Для простоты преобразования положим, что каждое слово может встречаться в тексте не более 9 раз. Длина слова – не более 10 символов (для экономии места контроль количества вводимых символов не производится). Слова в файле разделяются одним пробелом. Также для сокращения текста программы считаем, что имя входного файла фиксировано – inFile.txt.
— Регулярная проверка качества ссылок по более чем 100 показателям и ежедневный пересчет показателей качества проекта.
— Все известные форматы ссылок: арендные ссылки, вечные ссылки, публикации (упоминания, мнения, отзывы, статьи, пресс-релизы).
— SeoHammer покажет, где рост или падение, а также запросы, на которые нужно обратить внимание.
SeoHammer еще предоставляет технологию Буст, она ускоряет продвижение в десятки раз, а первые результаты появляются уже в течение первых 7 дней. Зарегистрироваться и Начать продвижение
Программа построения лексикографического дерева prg_12_78.asm имеет достаточно большой размер, в связи с чем ее текст вынесен на дискету.
Бинарные деревья – не единственный вид деревьев, которые могут быть использованы в ваших программах. В литературе можно ознакомиться с представлениями деревьев, отличных от бинарных. Мы не будем развивать далее проблему представления деревьев, хотя, честно говоря, очень хочется. За кадром остались такие важные проблемы, как балансировка деревьев, работа с В-деревьями и т. д. После столь обстоятельного введения и наличия соответствующей литературы, вы сможете без особого труда решить эти и другие проблемы. Тем более, что на худой конец любое дерево можно преобразовать в бинарное и работать с ним, используя приемы, описанные в настоящем разделе.
В преддверии рассмотрения следующего материала отметим, что разработанная в этом разделе программа будет очень полезна в процессе построения различных транслирующих программ, частным случаем которых являются компиляторы. Лексикографические деревья можно с успехом использовать в процессе работы сканера, задачей которого, в частности, является выяснение принадлежности некоторого идентификатора к ключевым словам некоторого языка. Введите в файл infile.txt список ключевых слов (разделенных одним пробелом), запустите программу и в памяти вы получите лексикографическое дерево.