
Порядок байтов
Этот подход можно перенести и на структуры: записывайте значения членов структур в определенной последовательности, побайтово, без выравнивания. Неважно, какой порядок байтов вы изберете, – подойдет любой, лишь бы передатчик и приемник согласовали порядок байтов в передаче и количество байтов в каждом объекте. В следующей главе мы покажем несколько инструментов для упаковки и распаковки данных.
Побайтовая обработка может показаться довольно дорогим удовольствием, но в сравнении с вводом-выводом, при котором необходима упаковка и распаковка данных, потери времени окажутся незначительными. Представьте себе систему X Window, в которой клиент пишет данные с тем порядком байтов, что используется у него на машине, а сервер должен распаковывать все, что клиент посылает. На клиентском конце достигнута экономия в несколько инструкций, но сервер становится больше и сложнее, поскольку ему приходится обрабатывать одновременно данные с разными порядками байтов: ведь клиенты вполне могут иметь различные типы машин. В общем, сложностей куда больше. Кроме того, не забывайте, что это графическая оболочка, где расходы на распаковку байтов будут с лихвой перекрыты выполнением той графической операции, которую они содержат.
Система X Window воспринимает данные от клиента с любым порядком байтов: считается, что это забота сервера. А система Plan 9, наоборот, сама задает порядок байтов для отправки сообщений файл-серверу (или графическому серверу), а данные запаковываются и распаковываются неким универсальным кодом вроде приведенного выше. На практике определить временные затраты во время исполнения оказывается практически невозможно; можно только сказать, что на фоне ввода-вывода упаковка данных оказывается малозаметной.
Java – язык более высокого уровня, чем С и C++, в нем порядок байтов скрыт совсем. Библиотеки представляют интерфейс Serializable, который определяет, как элементы данных пакуются для передачи.
Однако, если вы пишете на С или C++, всю работу придется выполнять самостоятельно. Главное, что можно сказать про побайтовую обработку: она решает имеющуюся проблему для всех машин с 8-битовыми байтами, причем решает без участия flifdef. Мы еще вернемся к этой теме в следующей главе.
Итак, лучшим решением нередко оказывается преобразование информации в текстовый формат, который (не считая проблемы CRLF) является абсолютно переносимым: не существует никаких неопределенностей с его представлением. Однако и текстовый формат не является панацеей. Время и размер для некоторых программ могут быть критичны, кроме того, часть данных, особенно числа с плавающей точкой, могут потерять точность при округлениях в процессе передачи через printf и scanf.
— Регулярная проверка качества ссылок по более чем 100 показателям и ежедневный пересчет показателей качества проекта.
— Все известные форматы ссылок: арендные ссылки, вечные ссылки, публикации (упоминания, мнения, отзывы, статьи, пресс-релизы).
— SeoHammer покажет, где рост или падение, а также запросы, на которые нужно обратить внимание.
SeoHammer еще предоставляет технологию Буст, она ускоряет продвижение в десятки раз, а первые результаты появляются уже в течение первых 7 дней. Зарегистрироваться и Начать продвижение
Если вам надо передавать числа с плавающей точкой, особо заботясь о точности, убедитесь, что у вас есть хорошая библиотека форматированного ввода-вывода; такие библиотеки существуют, просто ее может не оказаться конкретно в вашей системе. Особенно сложно представлять числа с плавающей точкой для переноса их в двоичном формате, но при должном внимании текст может эту проблему решить.
Существует один тонкий момент, связанный с использованием стандартных функций для обработки двоичных файлов, – эти файлы необходимо открывать в двоичном режиме:
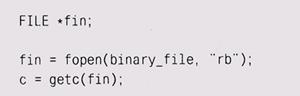
Если 'b' опущено, то в большинстве систем Unix это ни на что не повлияет, но в системах Windows первый встретившийся во вводе байт 1 Control-Z (восьмеричный 032, шестнадцатеричный 1А) прервет чтение! (такое происходило у нас с программой strings из главы 5). В то же время при использовании двоичного режима для чтения текстовых файлов; вам придется вставлять символы \r во ввод и убирать их из вывода.