
Многопроцессорные архитектуры
В действительности, оперативная память имеет конечную, и небольшую по сравнению с циклом центрального процессора, скорость доступа. Даже один современный процессор легко может занять все циклы доступа ОЗУ, а несколько процессоров будут непроизводительно тратить время, ожидая доступа к памяти. Многопортовое ОЗУ могло бы решить эту проблему, но такая память намного дороже обычной, однопортовой, и применяется лишь в особых случаях и в небольших объемах.
Одно из основных решений, позволяющих согласовать скорости ЦПУ и ОЗУ, – это снабжение процессоров высокоскоростными кэшами команд и данных. Такие кэши нередко делают не только для центральных процессоров, но и для адаптеров шин внешних устройств. Это значительно уменьшает количество обращений к ОЗУ, однако мешает решению задачи, ради которой мы и объединяли процессоры в единую систему: обмена данными между потоками, исполняющимися на разных процессорах (рис. 6.2).
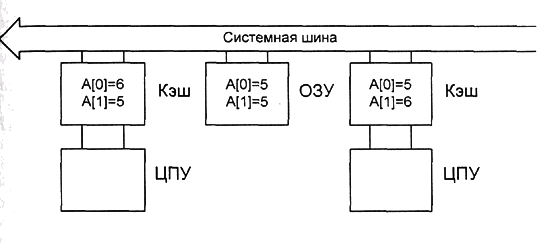
Рис. 6.2. Некогерентный кэш
Большинство контроллеров кэшей современных процессоров предоставляют средства обеспечения когерентности кэша – синхронизацию содержимого кэш-памятей нескольких процессоров без обязательной записи данных в основное ОЗУ.
Суперскалярные процессоры, у которых порядок реального исполнения операций может не совпадать с порядком, в котором соответствующие команды следуют в программе, дополнительно усугубляют проблему.
Порядок доступа к памяти в SPARC
Современные процессоры предоставляют возможность управлять порядком доступа команд к памяти. Например, у микропроцессоров SPARCvQ [www.sparc.com v9] определены три режима работы с памятью (модели памяти), переключаемые битами в статусном регистре процессора.
Свободный доступ к памяти (RMO, Relaxed Memory Order), когда процессор использует все средства кэширования и динамического переупорядочения команд, и не пытается обеспечить никаких требований к упорядоченности выбор-ки и сохранению операндов в основной памяти.
Частично упорядоченный доступ (PSO, Partial Store Order), когда процессор по-прежнему использует и кэширование, и переупорядочивание, но в потоке команд могут встречаться команды MEMBAR. Встретив такую команду, сор обязан гарантировать, что все операции чтения и записи из памяти, закодированные до этой команды, будут исполнены (в данном случае под исполнением подразумевается перенос результатов всех операций из кэша в ОЗУ), д0 того, как процессор попытается произвести любую из операций доступа к памяти, следующих за MEMBAR.
Полностью упорядоченный доступ (TSO, Total Store Order), когда процессор гарантирует, что операции доступа к памяти будут обращаться к основному ОЗУ в точности в том порядке, в котором закодированы.
— Регулярная проверка качества ссылок по более чем 100 показателям и ежедневный пересчет показателей качества проекта.
— Все известные форматы ссылок: арендные ссылки, вечные ссылки, публикации (упоминания, мнения, отзывы, статьи, пресс-релизы).
— SeoHammer покажет, где рост или падение, а также запросы, на которые нужно обратить внимание.
SeoHammer еще предоставляет технологию Буст, она ускоряет продвижение в десятки раз, а первые результаты появляются уже в течение первых 7 дней. Зарегистрироваться и Начать продвижение
Каждый следующий режим повышает уверенность программиста в том, что его программа прочитает из памяти именно то, что туда записал другой процессор, но одновременно приводит и к падению производительности. Наибольший проигрыш обеспечивает наивная реализация режима TSO, когда мы просто выключаем и динамическое переупорядочение команд, и кэширование данных (кэширование кода можно оставить, если только мы не пытаемся исполнить код, который подвергается параллельной модификации другим задатчиком шины).
Другим узким местом многопроцессорных систем является системная шина. Современные компьютеры общего назначения, как правило, имеют шинную архитектуру, т. е. и процессоры, и ОЗУ, и адаптеры шин внешних устройств (PCI и т. д.) соединены общей магистралью данных, системной шиной или системной магистралью. В каждый момент магистраль может занимать только пара устройств, задатчик и ведомый (рис. 6.3). Обычно, задатчиком служит процессор – как центральный, так и канальный – или контроллер ПДП, а ведомым может быть память или периферийное устройство. При синхронизации содержимого кэшей процессорный модуль также может оказаться в роли ведомого.
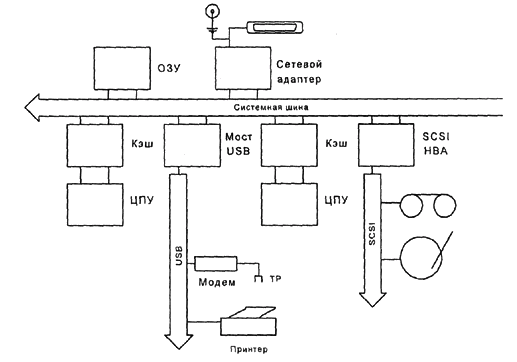
Рис. 6.3. Шинная архитектура