
Многопроцессорные архитектуры
При гиперкубическом соединении, количество узлов N пропорционально степени двойки, а каждый узел имеет log2N соединений с другими узлами. Каждый узел способен не только обмениваться сообщениями с непосредственными соседями по топологии, но и маршрутизировать сообщения между узлами, не имеющими прямого соединения. Самый длинный путь между узлами, находящимися в противоположных вершинах куба, имеет длину log2N и не является единственным (рис. 6.6). Благодаря множественности путей, маршрутизаторы могут выбирать для каждого сообщения наименее загруженный в данный момент путь или обходить отказавшие узлы.
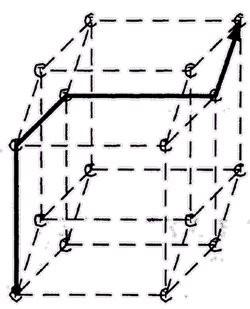
Рис. 6.6. Самый длинный путь в гиперкубе
Массивно параллельные системы Cray/SGI Origin
Узлы суперкомпьютеров семейства Cray/SGI Origin соединены в гиперкуб каналами с пропускной способностью 1 Гбайт/с. Адаптеры соединений обеспечивают не просто обмен данными, а прозрачный (хотя и с падением производительности) доступ процессоров каждого из узлов к оперативной памяти других узлов и обеспечение когерентности процессорных кэшей.
Различие в скорости доступа к локальной памяти процессорного модуля и Других модулей является проблемой, и при неудачном распределении загрузки между модулями (таком, что межмодульные обращения будут часты) Приведет к значительному снижению производительности системы. Известны два основных пути смягчения этой проблемы.
- СОМА (Cache Only Memory Architecture) – архитектура памяти, при которой работа с ней происходит как с кэшем. Система переносит страницы памяти, с которой данный процессорный модуль работает чаще других, в его локальную память.
- CC-NUMA (Cache-Coherent Non-Uniform Memory Access) неоднородный доступ к памяти с обеспечением когерентности кэшей). В этой архитектуре адаптеры межмодульных соединений снабжаются собственной кэшпамятью, которая используется при обращениях к ОЗУ других модулей. Основная деятельность центрального коммутатора и каналов связи состоит в поддержании когерентности этих кэшей [www.ibm.com NUMA-Q].
Понятно, что обе эти архитектуры не решают в корне проблемы неоднородности доступа: для обеих можно построить такую последовательность межпроцессорных взаимодействий, которая промоет1 все кэши и перегрузит межмодульные связи, а в случае СОМА приведет к постоянной перекачке страниц памяти между модулями. То же самое, впрочем, справедливо и для симметричных многопроцессорных систем с общей шиной.
В качестве резюме можно лишь подчеркнуть, что масштабируемость (отношение производительности системы к количеству процессоров) многопроцессорных систем определяется в первую очередь природой задачи и уровнем параллелизма, заложенным в использованный для решения этой задачи алгоритм. Разные типы многопроцессорных систем и разные топологии межпроцессорных соединений пригодны и оптимальны для различных задач.
Промывание кэша – довольно распространенный термин. Это последовательность обращении, которая намного больше объема кэша и в которой нет ни одного повторного обращения к одной и той же странице, или очень мало таких обращении.