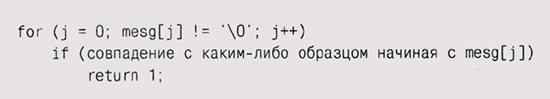Узкое место
Функция была написана с расчетом на эффективную работу, и действительно, для типичных случаев использования этот код оказывался достаточно быстрым, поскольку в нем используются хорошо оптимизированные библиотечные функции. Сначала вызывается strchr для поиска следующего вхождения первого символа образца, а затем strncmp – для проверки, совпадают ли остальные символы строки с остальными символами образца. Таким образом, изрядная часть сообщения пропускалась – до первого символа образца, и проверка начиналась только с него. Почему же возникли проблемы с производительностью?
На это есть несколько причин. Во-первых, strncmp получает в качестве аргумента длину образца, которая должна быть вычислена с помощью strlen. Однако длина образца у нас фиксирована, так что нет необходимости вычислять ее заново для каждого сообщения.
Во-вторых, strncmp содержит достаточно сложный внутренний цикл. В нем не только осуществляется сравнение байтов двух строк, но и производится поиск символа окончания строки \0 в обеих строках, да еще при этом отсчитывается длина строки, переданной в качестве параметра. Поскольку длина всех строк известна заранее (хотя и не в функции strncmp), в этих сложностях нет необходимости, мы знаем, что подсчеты верны, поэтому проверка на \0 – пустая трата времени.
В-третьих, strchr также сложна, поскольку она должна просматривать символы и при этом отслеживать \0, завершающий строку. При каждом конкретном вызове isspam сообщение фиксировано, поэтому время, использованное на поиск \0, опять же тратится зря, так как мы знаем, где окончится сообщение.
И наконец, даже если решить, что strncrnp, strchr и strlen достаточно эффективны сами по себе, затраты на вызов этих функций сравнимы с затратами на вычисления, которые они осуществляют. Более эффективно выполнять все действия в отдельной аккуратно написанной версии strstr, а не вызывать другие функции.
Трудности подобного рода – обычный источник проблем с производительностью: функция или интерфейс хорошо работают в обычных ситуациях, но недостаточно производительны для нестандартного случая, а именно этот случай и является основным для решаемой задачи. Существующая версия strstr работала вполне удовлетворительно, когда и образец, и строка были достаточно коротки и менялись при каждом новом вызове, но когда строка оказалась длинной и при этом фиксированной, издержки оказались чрезмерно высоки.
Исходя из вышеизложенных соображений, strstr была переписана так, чтобы и обход строк образца и сообщения, и поиск совпадений осуществлялись прямо в ней, причем без вызова дополнительных функций. Поведение получившейся реализации было предсказуемо: в некоторых случаях она работала несколько медленнее, но зато в спам-фильтре – гораздо быстрее, и что самое главное, не встретилось случаев, когда бы она работала очень медленно.
— Регулярная проверка качества ссылок по более чем 100 показателям и ежедневный пересчет показателей качества проекта.
— Все известные форматы ссылок: арендные ссылки, вечные ссылки, публикации (упоминания, мнения, отзывы, статьи, пресс-релизы).
— SeoHammer покажет, где рост или падение, а также запросы, на которые нужно обратить внимание.
SeoHammer еще предоставляет технологию Буст, она ускоряет продвижение в десятки раз, а первые результаты появляются уже в течение первых 7 дней. Зарегистрироваться и Начать продвижение
Для проверки корректности и производительности этой новой реализации был создан набор тестов производительности. В этот набор вошли не только обычные примеры вроде поиска слова в предложении, но и патологические случаи, такие как поиск образца из одной буквы х в строке из тысячи е и образца из тысячи х в строке с одним-един-ственным символом е, а надо сказать, что оба эти случая могли бы стать настоящей проблемой для непродуманной реализации. Подобные экстремальные случаи – ключевая часть оценки производительности.
Наша новая strstr была добавлена в библиотеку, и в результате спам-фильтр стал работать примерно на 30% быстрее, чем раньше, – хороший результат для изменения одной функции.
К сожалению, и это было слишком медленно.
Чтобы решить задачу, важно задавать себе правильные вопросы. До сего момента мы искали самый быстрый способ поиска текстового образца в строке. Но на самом деле наша проблема заключается в поиске большого фиксированного набора текстовых образцов в большой строке переменной длины. Если исходить из этого, то наша strstг не представляется, очевидно, лучшим решением.
Наиболее эффективный способ ускорить программу – применить алгоритм получше. Теперь, когда у нас есть четкое определение проблемы, можно подумать и об алгоритме.
Основной цикл:

Сканирует сообщение в точности npat раз; таким образом, в случае, если совпадений нет, он просматривает каждый байт сообщения npat раз, выполняя strlen(mesg)*npat сравнений.
Разумнее было бы поменять циклы местами, обходя сообщение единожды – во внешнем цикле, а сравнения со всеми образцами осуществлять в параллельном или вложенном цикле: