Узкое место
Повышение производительности достигнуто на основании простейшего наблюдения. Для того чтобы выяснить, не совпадает ли какой-нибудь образец с текстом сообщения, начиная с позиции j, нам не надо просматривать все образцы – интересовать нас будут только те, что начинаются с того же символа, что и mesg[ j ]. В первом приближении, имея 52 буквы верхнего и нижнего регистров, мы можем ожидать выполнения только strlen(mesg)*npat/52 сравнений. Поскольку буквы распределены не одинаково – слова гораздо чаще начинаются с s, чем с х, – мы, конечно, не добьемся увеличения производительности в 52 раза, но все же кое-что у нас получится. Так что фактически мы создали хэш-таблицу, в которой в качестве ключей используются первые буквы образцов.
Благодаря выполнению предварительных действий по созданию таблицы, определяющей, какой образец с какой буквы начинается, код isspam по-прежнему остался достаточно лаконичным:


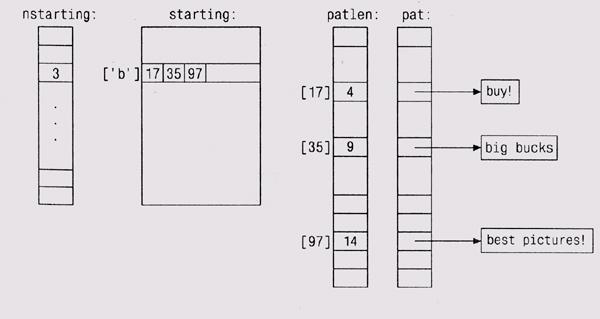
Двумерный массив starting[c][ ] хранит для каждого символа с индексы образцов, которые начинаются с этого символа, а его напарник nstarting[c] фиксирует, сколько образцов начинается с этого с. Без этих таблиц внутренний цикл выполнялся бы от 0 до npat, то есть около тысячи раз; в нашем варианте он выполняется от 0 до примерно 20. Наконец, элемент массива patlen[k] содержит вычисленный заранее результат strlen(pat[k]), то есть длину k-ro образца.
На приводимом ниже рисунке показаны эти структуры данных для трех образцов, начинающихся с буквы b.