
Хэш-таблицы
Поиск и возможная вставка комбинируются часто. Иначе приходится прилагать лишние усилия.
Если писать:
if (lookup("name") == NULL)
additem(newitem("name", value));
То хэш-функция вычисляется дважды.
Насколько большим должен быть массив? Основная идея заключается в том, что он должен быть достаточно большим, чтобы любая хэш-цепочка была бы длиной всего в несколько элементов и поиск занимал время О(1). Например, у компилятора размер массива должен быть порядка нескольких тысяч, так как в большом исходном файле – несколько тысяч строчек и вряд ли различных идентификаторов имеется больше, чем по одному на строчку кода.
Теперь нам нужно решить, что же наша хэш-функция, hash, будет вычислять. Она должна быть детерминированной, достаточно быстрой и распределять данные по массиву равномерно. Один из наиболее распространенных алгоритмов хэширования для строк получает хэш-значение, добавляя каждый байт строки к произведению предыдущего значения на некий фиксированный множитель (хэш). Умножение распределяет биты из нового байта по всему до сих пор не считанному значению, так что в конце цикла мы получим хорошую смесь входных байтов. Эмпирически установлено, что значения 31 и 37 являются хорошими множителями в хэш-функции для строк ASCII.

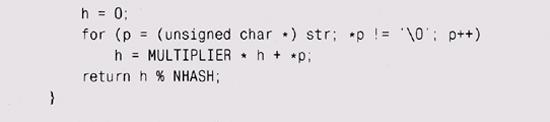
В вычислениях символы принимаются неотрицательными принудительно (тем, что используется тип unsigned char), так как ни в С, ни в C++ наличие знака у символов не регламентировано, а мы хотим, чтобы наша хэш-функция оставалась положительной.
Хэш-функция возвращает результат по модулю размера массива. Если хэш-функция распределяет данные равномерно, то точный размер массива неважен. Трудно, однако, гарантировать, что хэш-функция независима от размера массива, и даже у хорошей функции могут быть проблемы с некоторыми наборами входных данных.
Поэтому имеет смысл сделать размер массива простым числом, чтобы слегка подстраховаться, обеспечив отсутствие общих делителей у размера массива, хэш-мультипликатора и, возможно, значений данных.