
Алгоритм цепей Маркова
Элегантный способ выполнить подобную обработку – использовать технику, известную как алгоритм цепей Маркова. Ввод можно представить себе как последовательность перекрывающихся фраз; алгоритм разделяет каждую фразу на две части: префикс, состоящий из нескольких слов, и следующее за ним слово – суффикс (или окончание).
Алгоритм цепей Маркова создает выходные фразы, выбирая случайным образом суффикс, следующий за префиксом; все это в соответствии со статистикой текста-оригинала (в нашем случае). Хорошо выглядят фразы из трех слов, когда префикс из двух слов используется для подбора слова-суффикса:
присвоить w, и w2 значения двух первых слов текста печатать w, и w2 цикл: случайным образом выбрать w3 из слов, следующих за префиксом w, w2 в тексте печатать w3 заменить да/ и w2 на w2 и w-s повторить цикл
Для иллюстрации сгенерируем случайный текст, основываясь на нескольких предложениях из эпиграфа к этой главе и используя префикс из двух слов:
Show your flowcharts and conceal your tables and I will be mystified. Show your tables and your flowcharts will be obvious, (end)
Вот несколько пар слов, взятых из этого отрывка, и слова, которые следуют за ними:
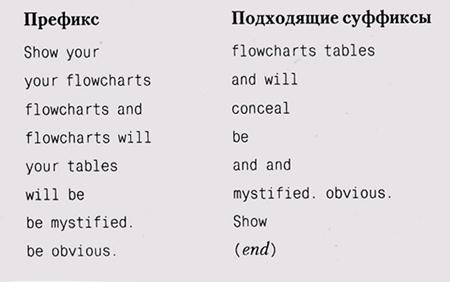
Обработка этого текста по предлагаемому алгоритму markov начинается с того, что будет напечатано Show your, после чего случайным образом будет выбрано или flowcharts, или tables. Если будет выбрано первое слово, то текущим префиксом станет your flowcharts, а следующим словом будет выбрано and или will. Если же выбранным окажется tables, то после него последует слово and. Так будет продолжаться до тех пор, пока не будет сгенерирована фраза заданного размера или в качестве суффикса не будет выбрано слово-метка конца ввода (end).
Наша программа прочтет отрывок английского текста и использует алгоритм markov для генерации нового текста, основываясь на частотах вхождения фраз фиксированной длины. Количество слов в префиксе, которое в разобранном примере равно двум, в нашей программе будет параметром. Если префикс укоротить, текст будет менее логичным, если длину префикса увеличить, наше творение будет походить на дословный пересказ вводимого текста. Для английского текста использование двух слов для выбора третьего дает разумный компромисс: сохраняется стиль прототипа и привносится достаточно своеобразия.
Что такое слово? Очевидный ответ – последовательность символов алфавита, однако нам было бы желательно сохранить и пунктуационные различия, то есть различать "words" и "words.". Приписывание знаков препинания к словам повышает качество генерируемого текста, вводя в него пунктуацию, а следовательно (косвенным образом), и грамматику, влияет на выбор слов; правда, при этом в текст могут просочиться несбалансированные разрозненные скобки и кавычки. Таким образом, мы определим "слово" как нечто, ограниченное с двух сторон пробелами, – при этом получится, что нет ограничений на используемый язык, а знаки пунктуации привязаны к словам. Поскольку в большинстве языков программирования имеются средства, позволяющие разбить текст на слова, разделенные пробелами, воплотить задуманное будет несложно.
— Регулярная проверка качества ссылок по более чем 100 показателям и ежедневный пересчет показателей качества проекта.
— Все известные форматы ссылок: арендные ссылки, вечные ссылки, публикации (упоминания, мнения, отзывы, статьи, пресс-релизы).
— SeoHammer покажет, где рост или падение, а также запросы, на которые нужно обратить внимание.
SeoHammer еще предоставляет технологию Буст, она ускоряет продвижение в десятки раз, а первые результаты появляются уже в течение первых 7 дней. Зарегистрироваться и Начать продвижение
Исходя из выбранного метода можно сказать, что все слова, фразы из двух слов и фразы из трех слов должны присутствовать во вводимом тексте, но появятся новые фразы из четырех и более слов. Ниже приведены несколько предложений, сгенерированных программой, разработке которой посвящена данная глава, полученных на основе текста седьмой главы книги "И восходит солнце" Эрнеста Хемингуэя:
As I started up the undershirt onto his chest black, and big stomach muscles bulging under the light. "You see them?" Below the line where his ribs stopped were two raised whate welts. "See on the forehead." "Oh, Brett, I love you." "Let's not talk. Talking's all bailge. I'm going away tomorrow". "Tomorrow?" "Yes. Didn't I say so? I am". " Let's have a drink, them."
Здесь нам повезло – пунктуация оказалась корректной, но этого могло и не случиться.