Создание структуры данных в языке С
Начнем с реализации на С. Для начала надо задать некоторые константы:

В этом описании определяются количество слов в префиксе (NPREF), размер массива хэш-таблицы (NHASH) и верхний предел количества генерируемых слов (MAXGEN). Если NPREF – константа времени компиляции, а не переменная времени исполнения, то управление хранением упрощается. Мы задали очень большой размер массива, поскольку программа должна быть способна воспринимать очень большие документы, возможно, даже целые книги. Мы выбрали NHASH = 4093, так что если во введенном. тексте имеется 10 000 различных префиксов (то есть пар слов), то среднестатистическая цепочка будет весьма короткой – два или три префикса. Чем больше размер, тем короче будет ожидаемая длина цепи и, следовательно, тем быстрее будет осуществляться поиск.
Эта программа создается для развлечения, поэтому производительность ее не критична, однако если мы сделаем слишком маленький массив, то программа не сможет обработать текст ожидаемого размера за разумное время; если же сделать его слишком большим, он может не уложиться в имеющуюся память.
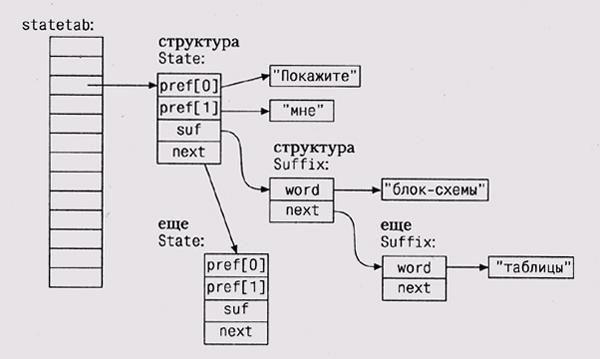
Префикс можно хранить как массив слов. Элементы хэш-таблицы будут представлены как тип данных State, ассоциирующий список Suffix с префиксом:

Графически структура данных выглядит так: