
Сохранение новых переменных
Многочисленные вспомогательные значения, рассчитываемые в ходе построения уравнения регрессии, можно сохранить как переменные и использовать в дальнейших расчетах.
- Для этого в диалоговом окне Linear Regression (Линейная регрессия) щелкните на кнопке Save (Сохранить).
Откроется диалоговое окно Linear Regression: Save (Линейная регрессия: Сохранение) как изображено на рисунке 16.3.
В 10 версии SPSS появилась новая возможность сохранять информацию о модели в так называемом XML-файле. В дальнейшем он может использоваться некоторыми дополнительными SPSS-продуктами (к примеру, Whatlf?).
Интересными здесь представляются опции Standardized (Стандартизированные значения) и Unstandardized (Нестандартизированные значения), которые находятся под рубрикой Predicted values (Прогнозируемые величины опции). При выборе опции Не стандартизированные значения будут рассчитывается значения у, которое соответствуют уравнению регрессии. При выборе опции Стандартизированные значения прогнозируемая величина нормализуется. SPSS автоматически присваивает новое имя каждой новообразованной переменной, независимо от того, рассчитываете ли Вы прогнозируемые значения, расстояния, прогнозируемые интервалы, остатки или какие-либо другие важные статистические характеристики. Нестандартизированным значениям SPSS присваивает имена pre_1 (predicted value), pre_2 и т.д., а стандартизированным zpr_1.
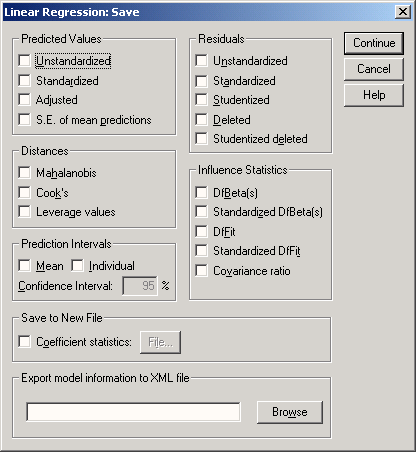
Рис. 16.3: Диалоговое окно Линейная регрессия: Сохранение
- Щелкните в диалоговом окне Linear Regression: Save (Линейная регрессия: Сохранение) в поле Predicted values (Прогнозируемые значения) на опции Unstandardized (Нестандартизированные значения).
- Подтвердите нажатием Continue (Далее) и в заключение ОК.
Вы увидите, что в редакторе данных была образована новая переменная под именем рrе_1 и добавлена в конец списка переменных в файле. Для объяснения значений, находящихся в переменной рrе_1, возьмем случай 5. Для случая 5 переменная рrе_1 содержит нестандартизированное прогнозируемое значение 263.11289. Это прогнозируемое значение слегка отличается в сторону увеличения от реального показателя содержания холестерина, взятого через один месяц (chol1) и равного 260. Нестандартизированное прогнозируемое значение для переменной chol1, так же как и другие значения переменной рге_1, было вычислено исходя из соответствующего уравнения регрессии:
chol1 = 0.863 * chol0 + 34.546Если мы в уравнение регрессии подставим исходное значение для chol0 (265), то получим:
chol1 = 0.863 - 265 + 34.546 = 263.241Небольшое отклонение от значения, хранящегося в переменной рге_1 объясняется тем, что SPSS использует в расчетах более точные значения, чем те, которые выводятся в окне просмотра результатов. На этом этапе мы еще раз проиллюстрируем возможность использования регрессии в качестве прогноза.
— Регулярная проверка качества ссылок по более чем 100 показателям и ежедневный пересчет показателей качества проекта.
— Все известные форматы ссылок: арендные ссылки, вечные ссылки, публикации (упоминания, мнения, отзывы, статьи, пресс-релизы).
— SeoHammer покажет, где рост или падение, а также запросы, на которые нужно обратить внимание.
SeoHammer еще предоставляет технологию Буст, она ускоряет продвижение в десятки раз, а первые результаты появляются уже в течение первых 7 дней. Зарегистрироваться и Начать продвижение
- Добавьте для этого в конец файла hyper.sav, еще два случая, используя фиктивные значения для переменной chol0. Пусть к примеру, это будут значения 282 и 314.
Мы исходим из того, что нам не известны значения показателя холестерина через месяц после начала лечения, и мы хотим спрогнозировать значение переменной chol1.
- Оставьте предыдущие установки без изменений и проведите новый расчет уравнения регрессии.
В конце списка переменных добавится переменная рге_2. Для нового добавленного случая (№175) для переменной chol1 будет предсказано значение 277.77567, а для случая №176 – значение 305.37620.