
Алгоритм формирования дерева решений по обучающей выборке
Ниже будет описан алгоритм формирования дерева решений по обучающей выборке, использованный в системе IDЗ. Задача, которую решает алгоритм, формулируется следующим образом. Задано:
- множество целевых непересекающихся классов {С1, С2,…, Сk};
- обучающая выборка S, в которой содержатся объекты более чем одного класса.
Алгоритм использует последовательность тестовых процедур, с помощью которых множество 5 разделяется на подмножества, содержащие объекты только одного класса. Ключевой в алгоритме является процедура построения дерева решений, в котором нетерминальные узлы соответствуют тестовым процедурам, каждая из которых имеет дело с единственным атрибутом объектов из обучающей выборки. Как вы увидите ниже, весь фокус состоит в в выборе этих тестов.
Пусть Т представляет любую тестовую процедуру, имеющую дело с одним из атрибутов, а {О1,O2,…,On} – множество допустимых выходных значений такой процедуры при ее применении к произвольному объекту х. Применение процедуры Т к объекту х будем обозначать как Т(х). Следовательно, процедура Т(х) разбивает множество S на составляющие { S1, S2,…, Sn}, такие, что: Si= {x|T(x) = Oi}.
Такое разделение графически представлено на рис. 20.3.
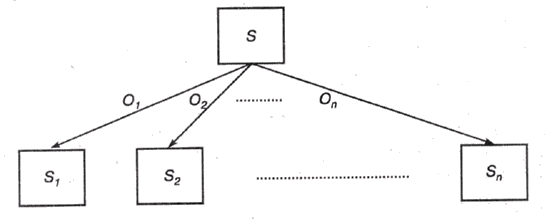
Рис. 20.3. Дерево разделения объектов обучающей выборки
Если рекурсивно заменять каждый узел Si, на рис. 20.3 поддеревом, то в результате будет построено дерево решений для обучающей выборки S. Как уже отмечалось выше, ключевым фактором в решении этой проблемы является выбор тестовой процедуры – для каждого поддерева нужно найти наиболее подходящий атрибут, по которому можно выполнять дальнейшее разделение объектов.
Квинлан (Quinlan) использует для этого заимствованное из теории информации понятие неопределенности. Неопределенность – это число, описывающее множество сообщений M= { m1, т2,…, тn}. Вероятность получения определенного сообщения mi из этого множества определим как р(тi). Объем информации, содержащейся в этом сообщении, будет в таком случае равен: I(mi) = -logp(mi).
Таким образом, объем информации в сообщении связан с вероятностью получения этого сообщения обратной монотонной зависимостью. Поскольку объем информации измеряется в битах, логарифм в этой формуле берется по основанию 2.
Неопределенность множества сообщений U(M) является взвешенной суммой количества информации в каждом отдельном сообщении, причем в качестве весовых коэффициентов используются вероятности получения соответствующих сообщений: U(М) = -Sumip[ (mi) logp(mi), i = 1,…, п. ]
— Регулярная проверка качества ссылок по более чем 100 показателям и ежедневный пересчет показателей качества проекта.
— Все известные форматы ссылок: арендные ссылки, вечные ссылки, публикации (упоминания, мнения, отзывы, статьи, пресс-релизы).
— SeoHammer покажет, где рост или падение, а также запросы, на которые нужно обратить внимание.
SeoHammer еще предоставляет технологию Буст, она ускоряет продвижение в десятки раз, а первые результаты появляются уже в течение первых 7 дней. Зарегистрироваться и Начать продвижение
Интуитивно ясно, что чем большую неожиданность представляет получение определенного сообщения из числа возможных, тем более оно информативно. Если все сообщения в множестве равновероятны, энтропия множества сообщений достигает максимума.
Тот способ, который использует Квинлан, базируется на следующих предположениях.
- Корректное дерево решения, сформированное по обучающей выборке S, будет разделять объекты в той же пропорции, в какой они представлены в этой обучающей выборке.
- Для какого-либо объекта, который нужно классифицировать, тестирующую процедуру можно рассматривать как источник сообщений об этом объекте.
Пусть Ni – количество объектов в S, принадлежащих классу Сi. Тогда вероятность того, что произвольный объект с, "выдернутый" из S, принадлежит классу Сi, можно оценить по формуле: p(c~Ci) = Ni/|S|, а количество информации, которое несет такое сообщение, равно: I (с ~ Сi) = -lоg2р(mi) (с ~ Сi) бит.