
PROLOG и MBASE. Правила поиска в языке PROLOG.
Ранее мы уже видели, что фразу, содержащую предположение, можно представить с помощью исчисления предикатов первого порядка. Фраза:
"Если философ выиграет у кого-нибудь в забеге, то этот человек будет им восхищен" в формализме предикатов приобретет вид формулы: (любой A) (любой Y)(PHILOSOPHER(X)^BEATS(X, Y)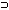 ADMJRE(Y, X)).
ADMJRE(Y, X)).
Эту формулу можно представить в конъюнктивной нормальной форме следующим образом:
{ADMIRE(Y, X), – ВЕАТS(Х, Y), › PHILOSOPHER(X)}.
Также было показано, что если записать это выражение таким образом, чтобы слева от оператора ":-" стоял единственный позитивный литерал, а справа – негативные литералы, то получится выражение, представляющее фразу Хорна в синтаксисе языка логического программирования PROLOG:
admire (Y, X): – philosopher (X), beats (X,Y).
Ниже мы рассмотрим, как организовать управление применением таких правил.
Правила поиска в языке PROLOG
Существует аналогия между выражениями вида:
admire(Y, X): – philosopher (X), beats (X,Y)
В языке PROLOG и консеквентной теоремой в системе PLANNER. При запросе "who admires whom?" ("кто кем восхищается?"), который может быть представлен в виде фразы:
: – admire(V, W).
Приведенное выше выражение интерпретируется следующим образом: "Для того чтобы показать, что Y восхищается X, покажите, что X является философом, а затем покажите, что X обогнал Y".
Цель, которая унифицируется с выражением admire(Y, X), может быть истолкована как вызов процедуры, а процесс унификации может рассматриваться как механизм передачи действительных параметров другим литералам, образующим тело процедуры. В данном случае не имеет значения, являются ли эти "параметры" переменными, как в представленном примере. Подцели в теле процедуры упорядочены. В языке PROLOG такое упорядочение называется правилом поиска слева направо.
В PLANNER и ранних системах, основанных на методе резолюций, цель легко достигается, если в базе данных содержатся утверждения:
philosopher (zeno) .beats (zeno, achilles).
Тогда получим ответ:
admire (achilles, zeno).
Если в базе данных содержится другая информация, касающаяся искомой цели, то программе может потребоваться выполнить обратный просмотр (backtrack), прежде чем добраться до цели. Обратный просмотр используется в том случае, когда нужно отменить присвоение значений переменным, выполненное при обработке некоторой подцели, поскольку это присвоение приводит к неудаче в обработке поздней подцели. Положим, что база данных содержит дополнительную фразу:
— Регулярная проверка качества ссылок по более чем 100 показателям и ежедневный пересчет показателей качества проекта.
— Все известные форматы ссылок: арендные ссылки, вечные ссылки, публикации (упоминания, мнения, отзывы, статьи, пресс-релизы).
— SeoHammer покажет, где рост или падение, а также запросы, на которые нужно обратить внимание.
SeoHammer еще предоставляет технологию Буст, она ускоряет продвижение в десятки раз, а первые результаты появляются уже в течение первых 7 дней. Зарегистрироваться и Начать продвижение
philosopher (socrates).
В этом случае, если эта формула отыщется прежде, чем формула:
philosopher(zeno).,
Обработка следующей подцели приведет к неудаче, а следовательно, нужно будет поискать другого философа. Объем работы, который придется выполнить системе в процессе достижения цели admire(V, W), зависит от количества альтернативных вариантов утверждений, касающихся философов, которые имеются в базе данных.
Предположим, что в базе данных содержатся факты еще о ста философах, т.е. в ней имеются сто других выражений в формате philosopher(X), в которых X отличается от zeno. Тогда в худшем случае программе потребуется 100 раз выполнить обратный просмотр, прежде чем будет найдено именно то утверждение, которое согласуется с целью.
База данных может содержать и другие правила, которые взаимодействуют с интересующим нас выражением admire (V, W). Например, можно положить, что утверждение "X обогнал Y" представляет транзитивное отношение. В этом случае в нашем распоряжении будет правило:
beats(X, Y): – beats(X, Z), beatsf Z, Y).
Можно также дать такое определение понятию "философ", что таковым будет считаться только тот, кого хотя бы однажды обогнала черепаха:
philosopher(X): – beats(Y, X), tortoise(Y).
Наличие этих правил очень усложнит пространство поиска и значительно увеличит количество случаев, когда придется выполнять обратный просмотр.
В следующем разделе описано одно из расширений языка PROLOG – система MBASE, на базе которой реализована программа МЕСНО для решения задач вузовского курса теоретической механики.