
Принцип кластерного анализа
В результате кластерного анализа при помощи предварительно заданных переменных формируются группы наблюдений. Под наблюдениями здесь понимаются отдельные личности (респонденты) или любые другие объекты. Члены одной группы (одного кластера) должны обладать схожими проявлениями переменных, а члены разных групп различными.
Наряду с кластеризацией наблюдений в SPSS предусмотрена кластеризация переменных. Здесь на основе заданных наблюдений образовываются группы переменных. Так как в принципе то же самое делает и факторный анализ (см. гл. 19), то в этой главе мы ограничимся рассмотрением только кластеризации наблюдений.
Для рассмотрения принципа кластерного анализа выберем сначала очень простой пример.
- Откройте файл bier.sav, который содержит некоторые данные о 17 сортах пива (см. рис. 20.1).
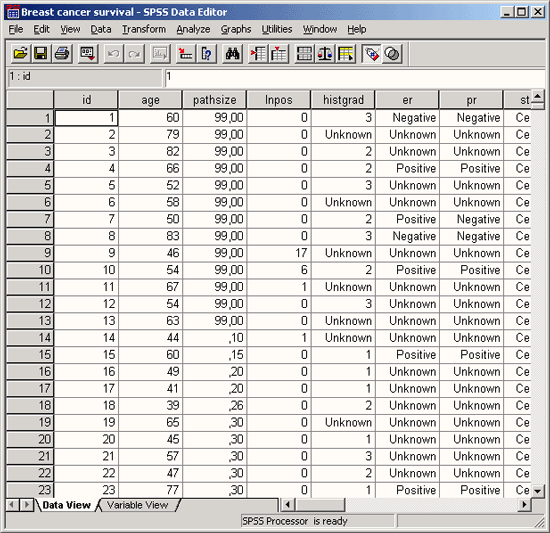
Рис. 20.1: Данные файла bier.sav в редакторе данных
Переменная herkunft (производитель) указывает на страну-производителя пива, где США закодированы с помощью единицы. Расходы (kosten) приведены в долларах США для емкости равной 12 унциям для жидкости (примерно одна треть литра); калорийность указана для одинакового количества пива. Содержание алкоголя приводится в процентах.
Возьмем переменные kalorien (калории) и kosten (расходы) и представим их при помощи простой диаграммы рассеяния.
- Выберите в меню Graphs (Графики) › Scalier… (Диаграмма рассеяния)
- Переменную kalorien (калории) поместите в поле оси х, а переменную kosten (расходы) в поле оси у, и для обозначения наблюдения используйте переменную bier (пиво).
- Через кнопку Options… (Опции) активируйте опцию Display Chart with case labels (Показывать график с метками наблюдений).
Вы получите диаграмму рассеяния, представленную на рисунке 20.2.
Рис. 20.2: Диаграмма рассеяния переменных kalorien (калории) и kosten (расходы)